Andreu Matoses Gimenez
PhD candidate in planning for robotics at the Department of Cognitive Robotics (CoR), TU Delft (Netherlands). I am supervised by Professor Javier Alonso-Mora and Professor Christian Pek. My research focuses on task and motion planning in multi-agent systems accounting for interaction and cooperation between other agents and humans. Feel free to contact me at A.MatosesGimenez (at) tudelft.nl
Before coming to Delft, I obtained my bachelor’s degree in aerospace engineering from Universitat Politècnica de València (Spain), and a master’s degree from KTH Royal institute of Technology (Sweden). After my MSc, I worked as a research engineer at KTH for Professor Dimos Dimarogonas’s group.

Latest News
- December 2025 | I will be presenting our work "SADCHER: Scheduling using Attention-based Dynamic Coalitions of Heterogeneous Robots in Real-Time" at MRS 2025, Singapore.
- October 2025 | Our workshop paper "Decentralized Aerial Manipulation of Cable-Suspended Load Using Multi-Agent RL" won best poster award at Cooperative Systems and Swarm Robotics in the Era of Generative IA, IROS 2025
- July 2025 | I will be attending RSS in Los Angeles.
Research
Cross-Entropy Optimization of Physically Grounded Task and Motion Plans
We use a parallelized physics simulator and cross entropy optimization to find optimal realizations of task and motion planning (TAMP) problems. This allows us to consider dynamics, contacts and the low level controllers that the real robot has, and their impact on the optimality and feasibility of the solutions.

SADCHER: Scheduling using Attention-based Dynamic Coalitions of Heterogeneous Robots in Real-Time
Sadcher is a real-time, imitation-learned task assignment framework for heterogeneous multi-robot teams with dynamic coalitions and task precedence. It predicts robot-task rewards using graph attention and transformers, then applies relaxed bipartite matching to produce feasible, high-quality schedules that scale and outperform learning/heuristic baselines; we also release a dataset of 250k optimal schedules.
Decentralized Aerial Manipulation of a Cable-Suspended Load Using Multi-Agent Reinforcement Learning
Decentralized MARL for 6-DoF control of a cable-suspended load with multiple MAVs, requiring no inter-drone communication and enabling scalable, onboard deployment. Combined with low-level controllers, it transfers robustly from simulation to reality, matching centralized performance while tolerating uncertainties and even loss of a drone.

Linear Temporal Logic (LTL) Planner for Agricultural Robotics
Implemented a ROS based linear temporal logic (LTL) planner for the CANOPIES ERC: Collaborative Paradigm for Human Workers and Multi-Robot Teams in Precision Agriculture Systems.
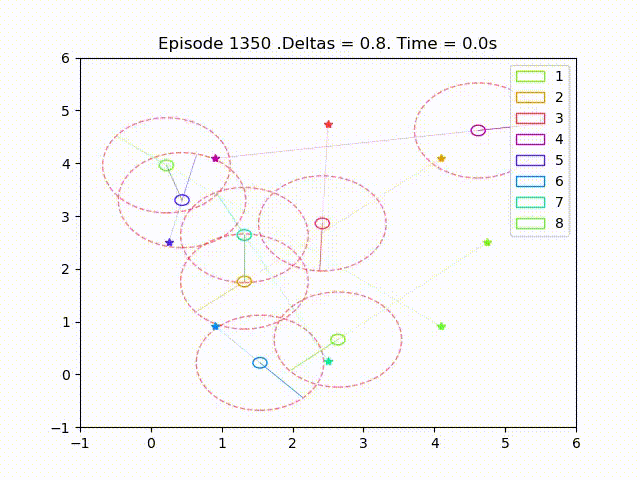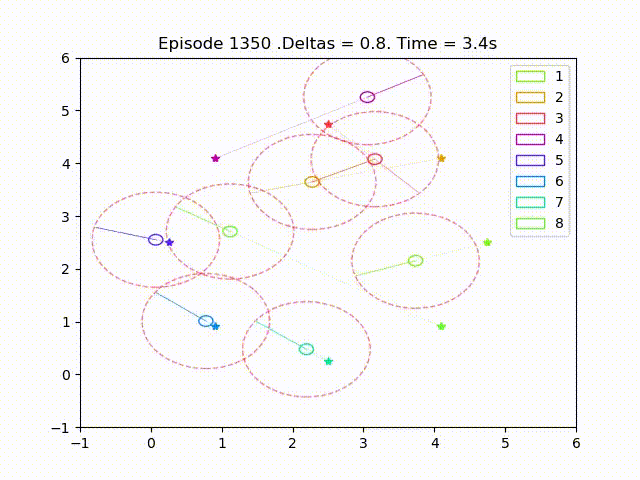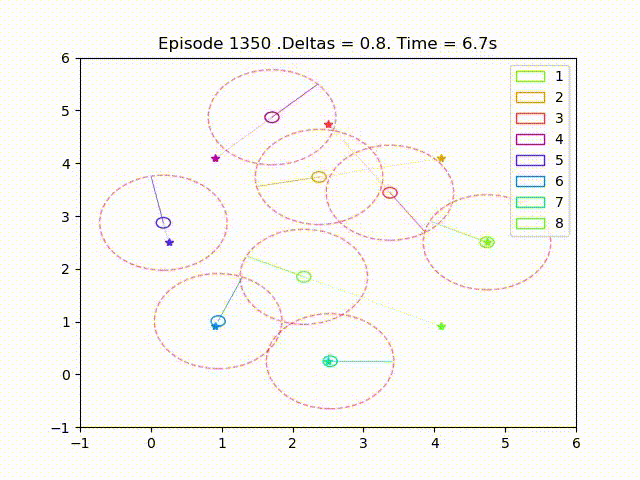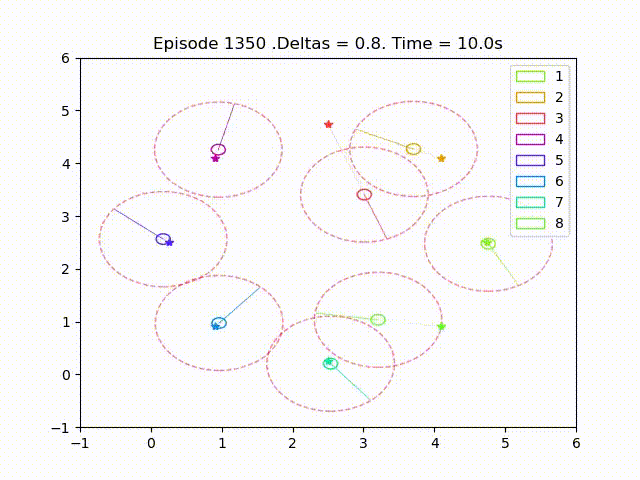
Scalable Multi-Agent Reinforcement Learning for Collision Avoidance
Scalable multi-agent reinforcement learning for formation control with collision avoidance. This work was my Master's Thesis while at KTH Royal Institute of Technology. The proposed method exploits the reward structure to enable local approximation of Q-functions and policy gradients, allowing for scalable training. We compare discrete and continuous policies and analyze the impact of the sensing radius on performance and collision avoidance.

ALPHA, a high altitude UAV
Design of an autonomous high altitude long endurance UAV to study optical phenomena in the upper atmosphere using scientific imaging instruments. Project under the KTH Space Physics department. Paper presented at ICAS 2022.